
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- swiftUI
- Reality Composer
- Xcode Cloud
- User Enrollment
- actor
- SF Symbols 3.0
- MDM
- Xcode Organizer
- Hand Action Detect
- METAL
- CoreML
- SWiFT
- NSUserActivity
- App Clip
- AR Quick Look
- async
- concurrency
- AVFoundation
- Mac
- WWDC 2021
- AppleEvent
- detent
- DooC
- Physical Audio
- DriverKit
- Hand Pose Detect
- profile
- Object Capture
- SF Symbols
- ProRAW
Archives
- Today
- Total
nyancoder
WWDC 2021 - Discover geometry-aware audio with the Physical Audio Spatialization Engine (PHASE) 본문
WWDC/WWDC 2021
WWDC 2021 - Discover geometry-aware audio with the Physical Audio Spatialization Engine (PHASE)
nyancoder 2021. 10. 20. 23:56원본 영상: https://developer.apple.com/videos/play/wwdc2021/10079/
Motivation
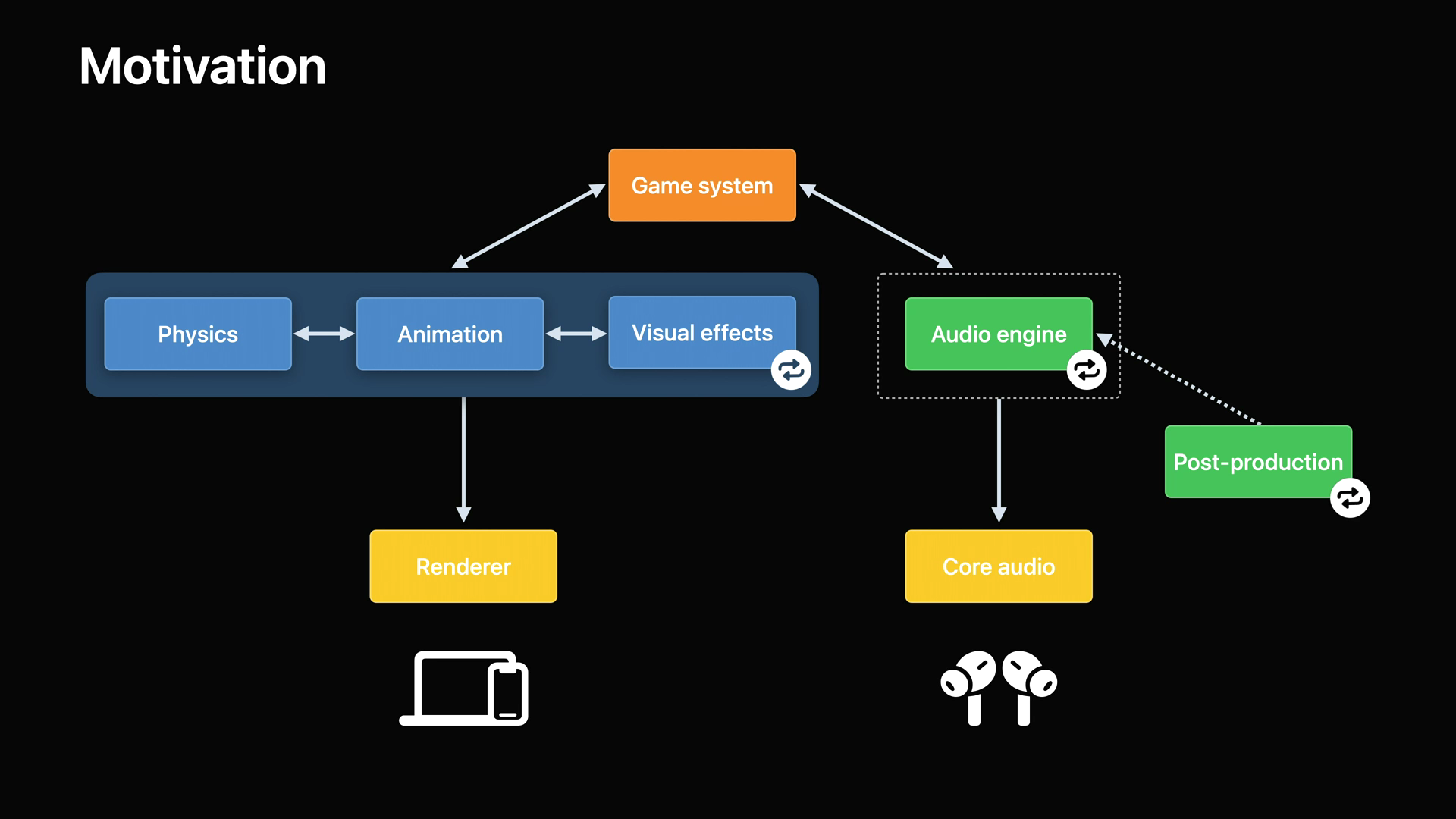
- 오늘날 게임에서 물리, 애니메이션, 시각 효과 등은 같은 엔진 내에서 서로 통신하고 처리하지만 대다수의 오디오 시스템은 일반적으로 나머지 부분과 별도로 구동됩니다.
- 오디오 리소스는 사후 제작되고 수작업으로 조정되어, 일반적으로 게임 플레이의 지연되는 오디오 경험으로 이어집니다.

- 더 나은 게임 오디오 경험을 제공하기 위해 오디오 시스템을 다른 하위 시스템과 더 가깝게 만들고자 하였습니다.
- 또한 모든 장치에서 일관된 공간 오디오 경험을 제공할 수 있는 앱을 더 쉽게 작성할 수 있도록 하고자 합니다.
Features

- 이제 새로운 오디오 프레임워크인 PHASE는 오디오 엔진에 지오메트리 정보를 제공합니다.
- 사운드 디자인 친화적인 이벤트 중심 오디오 재생 시스템을 구축하는데 도움을 줍니다.
- 모든 영역에서 일관된 공간 오디오 경험을 제공할 수 있는 애플리케이션을 작성할 수 있게 해 줍니다.
- 기존의 설루션 및 파이프라인과 통합될 수 있습니다.

- 일반적으로 사용되는 게임 오디오의 예로 건물과 강이 있는 야외의 예를 볼 것입니다.
- 건물 같은 객체는 오디오의 소스와 청취자 사이의 소리를 약화할 수 있으며, 이를 위해 개발자가 수동으로 적절히 사운드를 섞거나 감쇠합니다.

- 오디오 시스템이 자연스럽게 장면에 따라 자동으로 관리하는 것이 PHASE입니다.

- 새 프레임워크는 음원을 오디오 엔진에 기하학적 모양으로 전달할 수 있는 API를 제공합니다.
- 또한 소리의 방해 요소들의 재질도 선택할 수 있습니다.
- 야외에 있거나 실내에 있는 등의 환경에 따라 소리의 잔향이나 반사를 설정할 수 있습니다.
- 이처럼 다양한 음원과 방해 요소, 청취자의 위치를 전달하면 PHASE가 자동으로 음원의 폐색 및 확산 효과를 모델링합니다.

- PHASE는 이벤트 기반 재생 시스템도 제공합니다.
- 사운드 이벤트는 PHASE에서 오디오 재생 이벤트를 설명하기 위한 기본 단위입니다.
- 오디오 리소스의 선택, 혼합, 재생을 캡슐화합니다.
- 사운드 이벤트는 한번 재생, 반복 재생과 같은 단순한 이벤트나 재생 이벤트의 트리를 혼합하거나 전환할 수 있는 복잡한 시퀀스에 이르기까지 다양합니다.
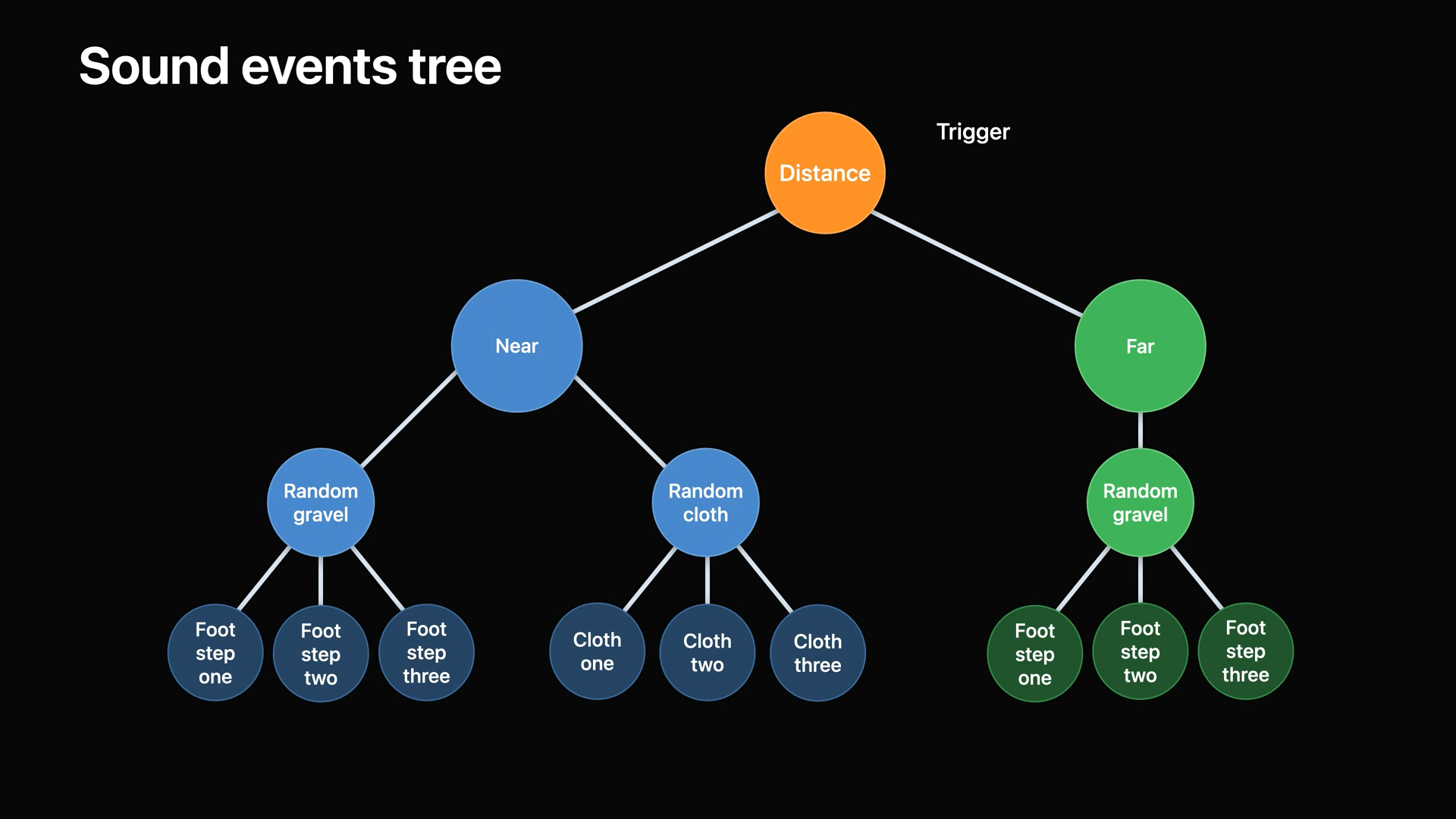
- 발자국을 연주하는 간단한 예를 보면 우선 세 가지 자갈 위의 발자국 소리 중에서 임의의 것을 자동으로 선택하는 노드가 있습니다.
- 천이 스치는 소리 또한 동일하게 임의로 선택하는 노드를 둘 수 있습니다.
- 두 이벤트 트리를 "가까운" 다른 나무에 연결하여 옷감이 바스락거리는 소리와 발자국 소리가 혼합된 소리를 재생할 수 있습니다.
- 캐릭터가 멀리 떨어져 있을 때 다른 소리를 재생하기 위해 "far"라는 노드를 가질 수 있습니다.
- 이처럼 사용자 상호 작용이나 물리 및 애니메이션에 의해 발생할 수 있는 복잡한 재생 이벤트를 구축할 수 있습니다.

- PHASE를 사용하면 간단한 채널 구성이나 방향과 위치가 있는 3D 공간 또는 방향은 있지만 위치가 없는 주변 소리를 재생할 수 있습니다.
- 엔진은 iOS, macOS 장치, Air Pods 헤드폰 제품군에서 이미 사용할 수 있는 공간 오디오 렌더링 기능을 기반으로 합니다.
- 이를 통해 지원되는 모든 장치에서 일관된 공간 오디오 경험을 자동으로 제공하는 애플리케이션을 구축할 수 있습니다.
Concepts
- PHASE API는 리소스를 관리하는 엔진, 재생을 제어하는 노드, 공간화를 제어하는 믹서의 세 가지로 구성됩니다.

- PHASE 엔진은 리소스 관리, 씬 그래프, 렌더링 상태의 세 가지로 구성됩니다.

- 엔진 수명 주기 동안 엔진에 리소스를 등록하거나 해제할 수 있습니다.
- PHASE는 사운드 리소스 및 사운드 이벤트 리소스 등록을 지원합니다.
- 사운드 리소스는 오디오 파일에서 직접 로드하거나 자체 리소스에 raw 오디오 데이터로 포함하고 엔진에 로드할 수 있습니다.
- 사운드 이벤트 리소스는 사운드 재생을 제어하는 하나 이상의 계층적 노드와 공간화를 제어하는 다운스트림 믹서의 모음입니다.
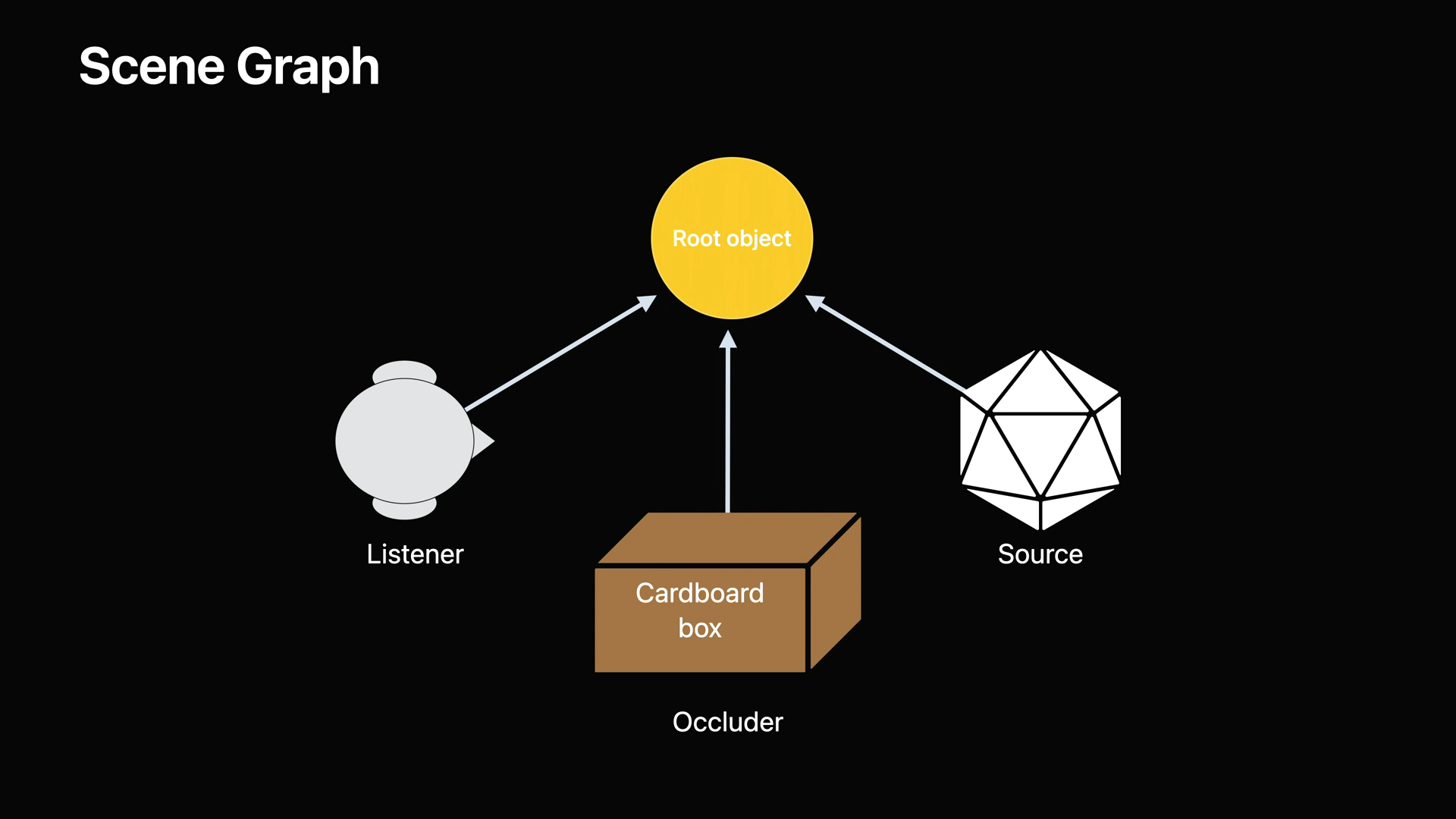
- 장면 그래프는 시뮬레이션에 참여하는 객체의 계층 구조이며 청자, 소리 발생원, 소리 방해물이 포함됩니다.
- 청자는 공간에서 시뮬레이션을 듣는 위치를 나타내는 객체입니다.
- 소리 발생원은 사운드가 발생하는 위치를 나타내는 개체이며, PHASE는 포인트 소스와 체적 소스를 모두 지원합니다.
- 소리 방해물은 환경을 통과할 때 사운드 전송에 영향을 미치는 물체의 공간을 나타내는 객체입니다.
- 소리 방해물에는 사운드를 흡수하고 전달하는 방식에 영향을 주는 재질도 할당됩니다.
- 장면에 개체를 추가할 때 개체를 계층 구조로 구성하고 엔진의 루트 개체에 직, 간접적으로 연결합니다.

- 렌더링 상태는 재생 사운드 이벤트 및 오디오 IO를 관리합니다.
- 엔진을 처음 생성하면 오디오 IO가 비활성화됩니다.
- 이때 오디오 IO를 실행할 필요 없이 리소스를 등록하고, 장면 그래프를 작성하고, 사운드 이벤트를 구성하고, 기타 엔진 작업을 수행할 수 있습니다.
- 사운드 이벤트를 재생할 준비가 되면 오디오 IO 엔진을 시작할 수 있습니다.
- 마찬가지로 사운드 이벤트 재생이 끝나면 엔진을 중지할 수 있습니다.
- 이렇게 하면 오디오 IO가 중지되고 재생 중인 사운드 이벤트가 중지됩니다.

- PHASE의 노드는 오디오 콘텐츠의 재생을 제어하며, 오디오 재생을 생성하거나 제어하는 개체의 계층적 컬렉션입니다.
- Generator 노드는 오디오를 생성하며 계층에서 항상 말단 노드입니다.
- 제어 노드는 Generator를 선택, 혼합 및 매개변수화 하는 방법에 대한 논리를 설정합니다.
- 제어 노드는 항상 상위 노드이며 복잡한 사운드 시나리오를 위한 계층으로 구성될 수 있습니다.

- 샘플러 노드는 일종의 생성기 노드이며, 등록된 사운드 자산을 재생합니다.
- 샘플러 노드는 구성되면 몇 가지 기본 속성을 설정하여 올바르게 재생되도록 합니다.

- 재생 모드는 오디오 파일이 재생되는 방식을 결정합니다.
- OneShot으로 설정하면 오디오 파일이 한 번 재생되고 자동으로 중지됩니다.
- 반복으로 설정하면 샘플러를 명시적으로 중지할 때까지 오디오 파일이 무기한 재생됩니다.

- Cull Option은 PHASE에게 소리가 들리지 않게 될 때 무엇을 해야 하는지 알려줍니다.
- 종료로 설정하면 소리가 들리지 않게 되면 자동으로 소리가 멈춥니다.
- 절전으로 설정하면 소리가 들리지 않게 되면 소리가 중지되며, 소리가 들리게 될 때 다시 재생을 시작합니다.
- 이를 이용하면 엔진에 의해 컬링 될 때 사운드를 수동으로 시작 및 중지할 필요가 없습니다.

- 보정 레벨은 사운드의 실제 레벨을 데시벨 SPL로 설정합니다.

- PHASE는 랜덤, 스위치, 블렌드, 컨테이너 노드의 4가지 유형의 제어 노드를 지원합니다.

- 랜덤 노드는 가중 랜덤 선택에 따라 자식 중 하나를 선택합니다.
- 위의 예제에서는 사운드 이벤트가 트리거 될 때 왼쪽 샘플러와 오른쪽 샘플러가 4:1의 재생 확률을 갖습니다.
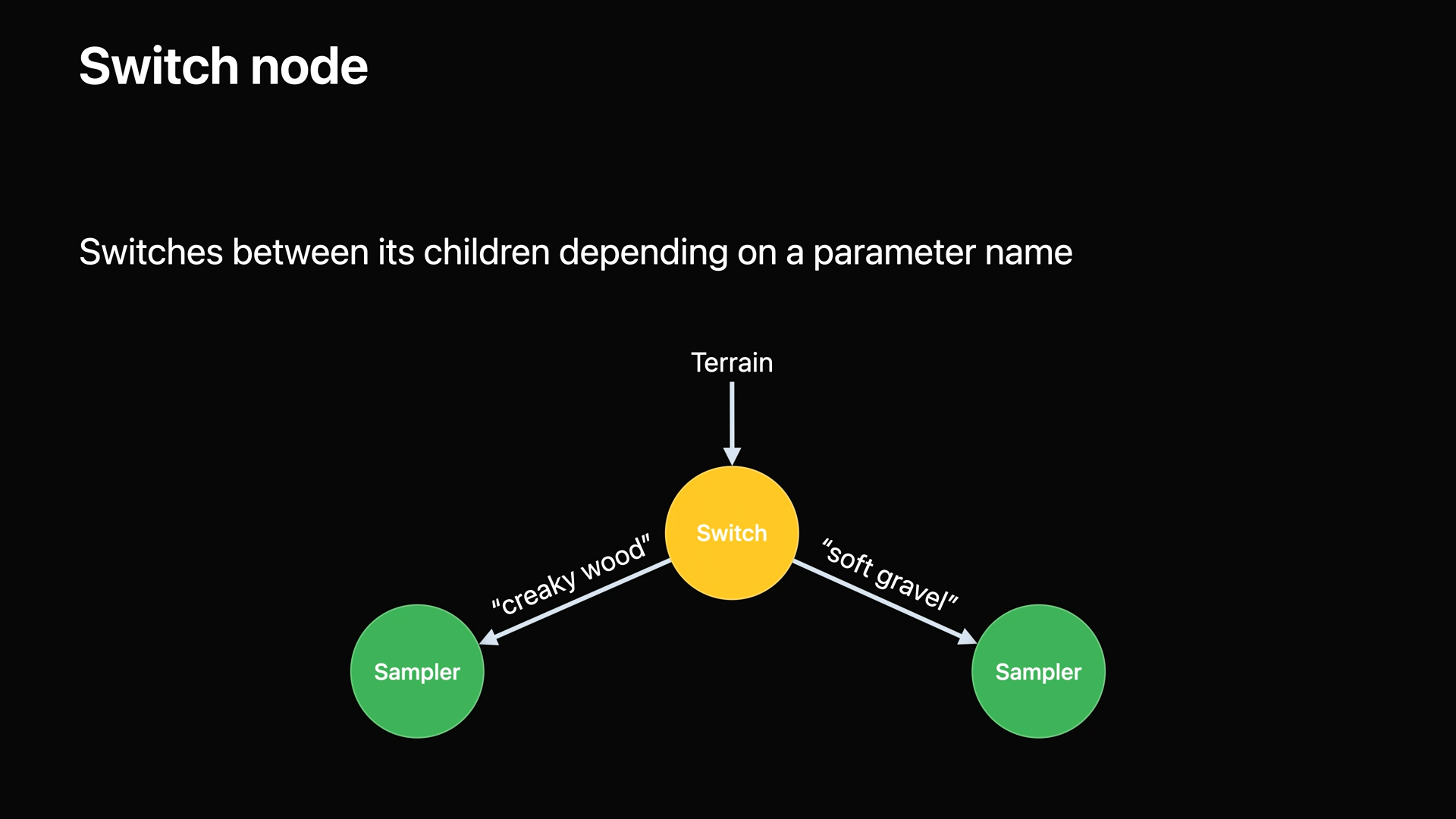
- 스위치 노드는 매개변수 이름을 기반으로 전환합니다.
- 위의 예에서는 지형 스위치가 "creaky wood"에서 "soft gravel로 변경할 수 있습니다.
- 다음에 사운드 이벤트가 발생하면 매개변수 이름과 일치하는 샘플러가 선택됩니다.

- 블렌드 노드는 매개변수 값을 기반으로 자식 간에 블렌딩 됩니다.
- 위의 예에서는 블렌드 노드에 wetness 매개변수를 할당하여 "Footstep"과 "Splash"간의 혼합 정도를 설정합니다.

- 컨테이너 노드는 모든 자식을 한 번에 재생합니다.
- 위의 예에서는 "footstep"과 "clothing" 샘플러가 동시에 재생됩니다.

- PHASE의 믹서는 오디오 콘텐츠의 공간화를 제어합니다.
- PHASE는 현재 채널, 환경, 공간 믹서를 지원합니다.

- 채널 믹서는 공간화 및 환경 효과 없이 오디오를 렌더링 합니다.
- 스테레오 음악 또는 센터 채널 대화와 같이 출력 장치에 직접 렌더링해야 하는 일반 콘텐츠에 채널 믹서를 사용합니다.

- 환경 믹서는 외부화와 함께 오디오를 렌더링 하지만 거리 모델링이나 환경 효과는 없습니다.
- 청취자가 머리를 돌리면 소리는 공간의 동일한 상대 위치에서 계속 나옵니다.
- 다중 채널 콘텐츠에 앰비언트 믹서를 사용하면 위치가 시뮬레이션되지는 않지만 여전히 공간의 어딘가에서 들리는 것처럼 들릴 것입니다.
- 예를 들어, 큰 숲에서 귀뚜라미가 지저귀는 소리 같은 배경음을 사용할 수 있습니다.

- 공간 믹서는 전체 공간화를 수행합니다.
- 음원이 청취자를 기준으로 움직이면 패닝, 거리 모델링, 지향성 모델링 알고리즘을 기반으로 인지된 위치, 레벨, 주파수 의 변화를 들을 수 있습니다.
- 지오메트리 인식 기반의 환경 효과가 소리 발생지와 청자 사이의 경로에 적용됩니다.
- 헤드폰을 착용하고 있다면 바이노럴 필터를 적용할 수도 있습니다.

- 공간 믹서는 두 가지 고유한 거리 모델링 알고리즘을 지원하며, 이를 이용하여 거리에 따른 자연 감쇠에 대한 확산 손실을 설정하거나 원하는 대로 효과를 높이거나 낮출 수도 있습니다.
- 예를 들어, 단순히 멀리서 대화를 듣는 경우 값을 낮추는 것이 유용할 수 있습니다.
- 스펙트럼의 다른 쪽 끝에는 거리에 따라 감쇠의 전체 조각 별 곡선 세그먼트를 추가할 수 있습니다.
- 예를 들어 범위의 시작과 끝에서 거리에 따라 소리가 줄어들지만, 중간 위치에서도 중요한 대화를 잘 들을 수 있도록 감쇠가 줄어드는 세그먼트 세트를 구성할 수 있습니다.
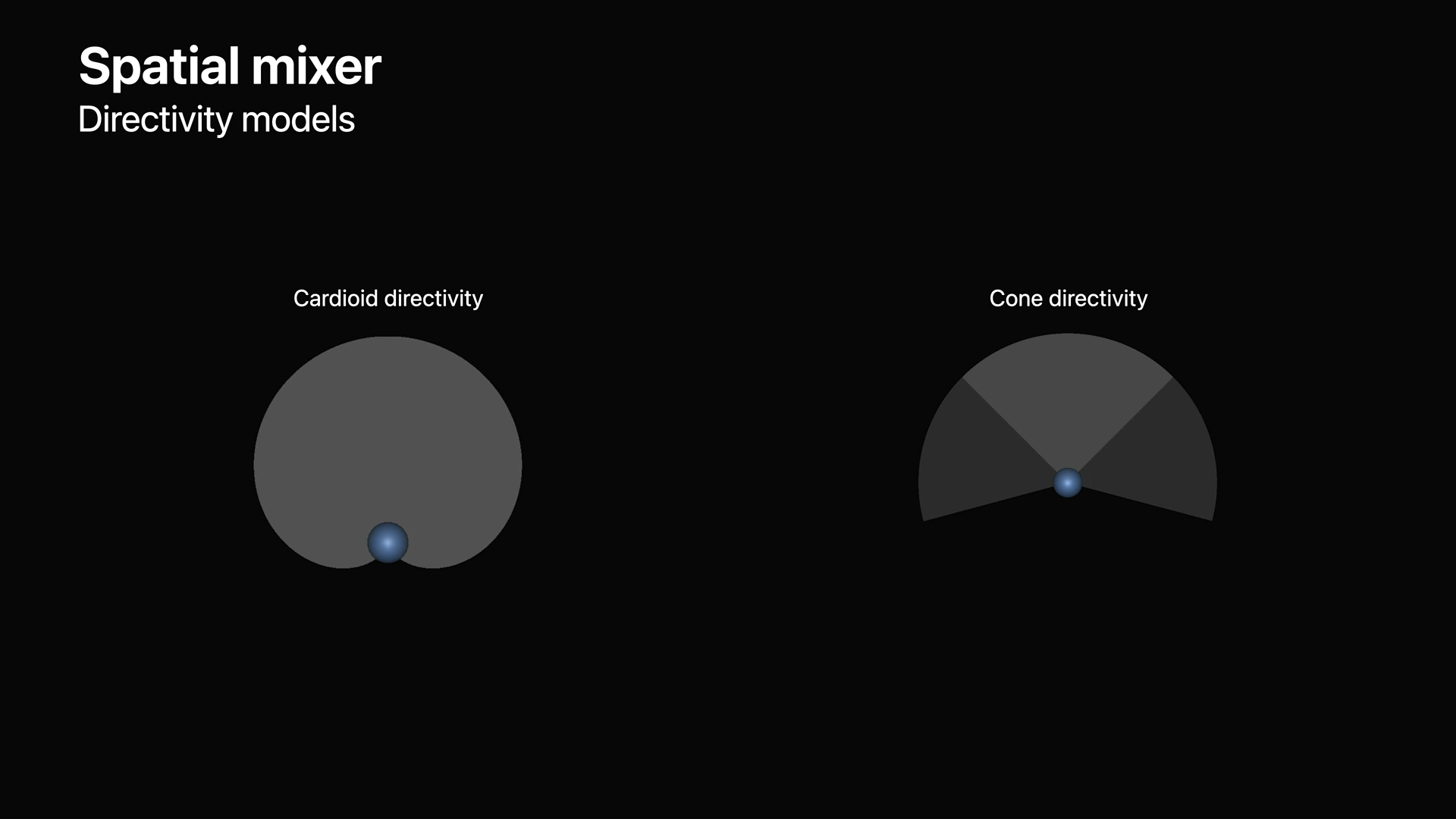
- 포인트 소스의 경우 공간 믹서는 두 가지 방향 모델링 알고리즘을 지원합니다.
- Cardioid 지향성 모델링을 추가할 수 있습니다.
- 몇 가지 간단한 수정을 사용하여 Cardioid 지향성 패턴을 가진 사람 또는 하이퍼 Cardioid 패턴을 가진 어쿠스틱 현악기의 사운드를 모델링할 수 있습니다.
- 원뿔 지향성 모델링을 추가할 수도 있으며, 이 모델에서 특정 각도 범위 내로 지향성 필터링을 제한할 수 있습니다.

- 공간 믹서는 공간 파이프라인을 기반으로 하는 지오메트리 인식 환경 효과도 지원합니다.
- 공간 파이프라인은 활성화 또는 비활성화할 환경 효과와 각각에 대한 전송 수준을 선택합니다.
- PHASE는 현재 직접 경로 전송, 초기 반사, 늦은 반향을 지원합니다.
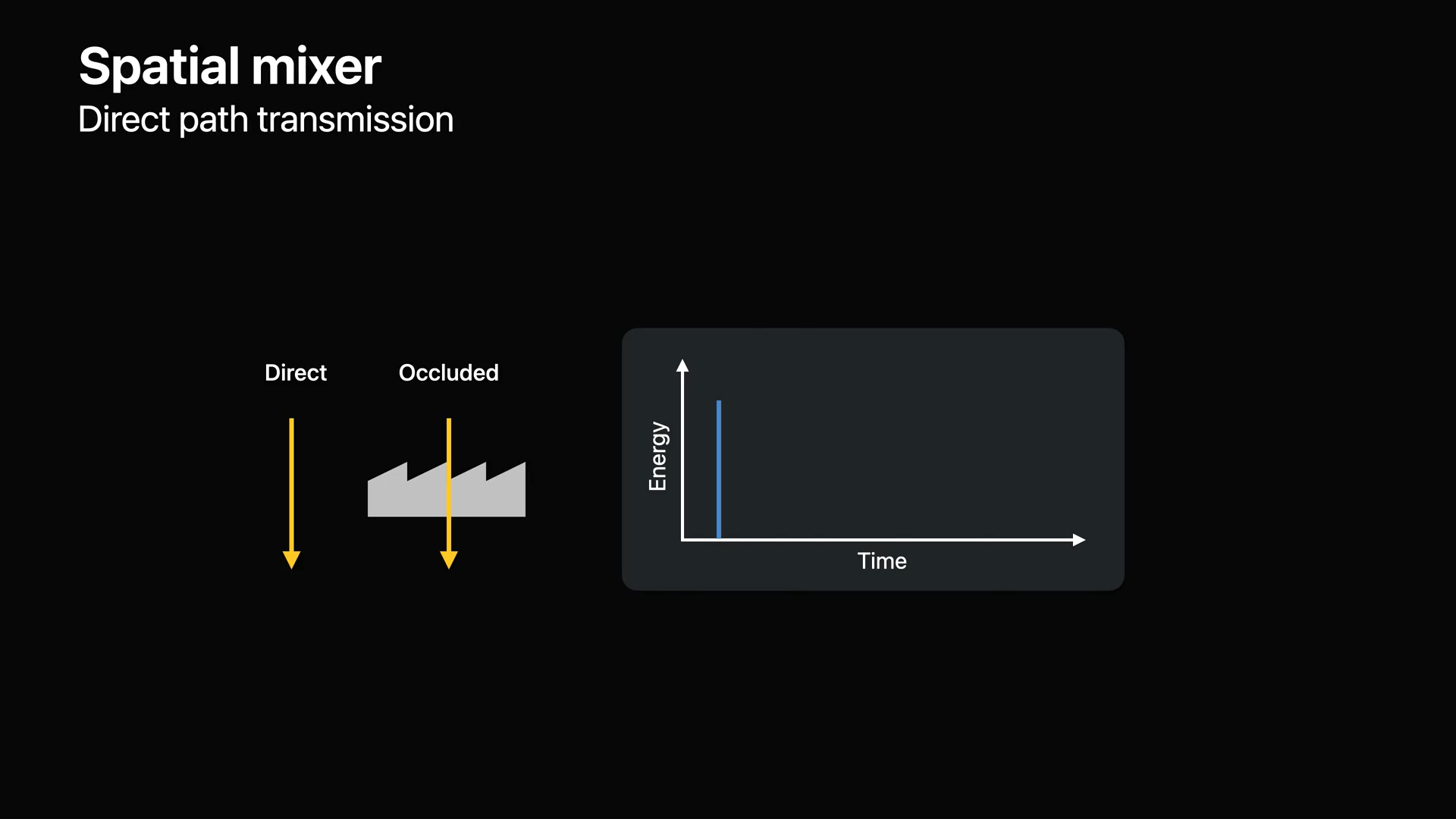
- 직접 경로 전송은 소스와 청취자 사이의 직접 및 폐색 경로를 렌더링 합니다.
- 폐색 된 사운드의 경우 일부 에너지는 재료에 의해 흡수되고 다른 에너지는 물체의 다른 면으로 전달됩니다.

- 초기 반사는 직접 경로에 강도 수정과 채색을 제공합니다.
- 일반적으로 벽과 바닥에서의 반사로 만들어지며 더 큰 공간에서는 눈에 띄는 반향이 더해집니다.

- 늦은 반향은 환경 사운드를 제공하며, 공간에서 확산된 에너지가 다시 모이는 것입니다.
- 방 크기와 모양에 대한 단서를 제공하는 것 외에도 공간감을 주는 역할도 합니다.
Sample use cases

- 이 장에서는 예제를 통한 오디오 파일 재생, 공간 오디오 경험 구축, 사운드 이벤트 구축을 볼 것입니다.
- 우선 오디오 파일을 재생하기 위해서는 PHASE 엔진 인스턴스를 생성해야 합니다.

- 오디오 파일에 대한 URL을 검색하고 PHASE 엔진에 사운드 리소스를 등록합니다.
- 나중에 이 리소스에 접근하기 위해 이름을 "drums"로 지정합니다.
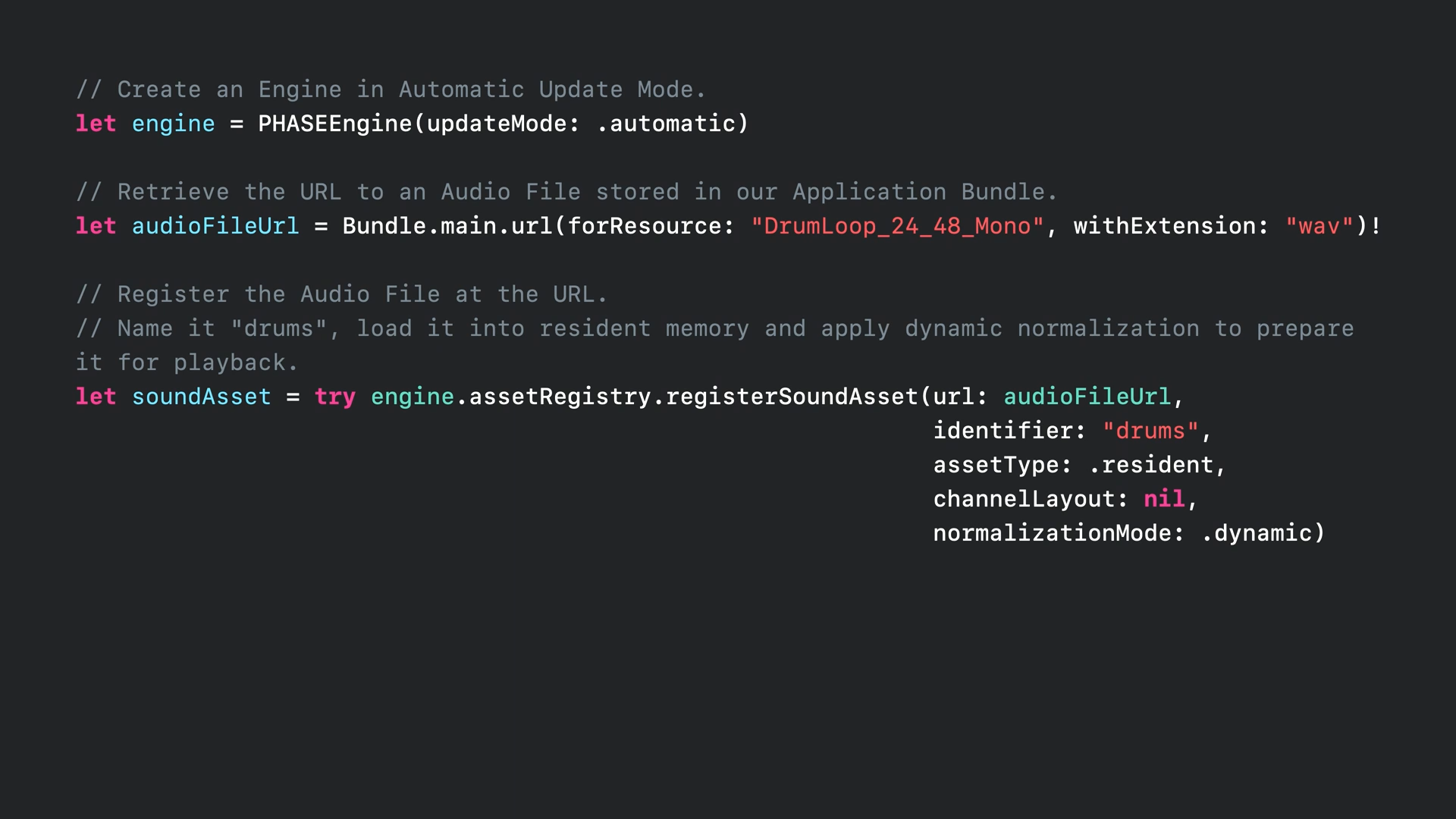
- 위 예제 코드를 보면 우선 일반적으로 선호되는 자동 업데이트 모드에서 PHASE 엔진 인스턴스를 생성합니다.
- 게임에서 프레임 업데이트와 더 정확한 동기화가 필요한 경우에는 수동 모드를 사용하는 것이 좋습니다.
- 다음으로, 애플리케이션 번들에 저장된 오디오 파일의 URL을 검색합니다.
- 그다음 엔진에 사운드 리소스를 등록합니다.
- 등록할 때는 나중에 참조할 수 있도록 사운드 리소스에 "drums"라는 고유한 이름을 지정합니다.
- 오디오 데이터가 작고 여러 번 재생해야 할 수 있기 때문에 상주 메모리에 미리 로드되도록 resident로 지정합니다.
- 출력 장치에서 보정된 음량에 대한 사운드 리소스를 정규화하도록 dynamic을 선택합니다.
- 일반적으로 입력을 정규화하는 것이 좋으며, 이를 통해서 샘플러에 콘텐츠를 할당하고 대상 출력 레벨을 설정하여 콘텐츠를 더 쉽게 혼합할 수 있습니다.
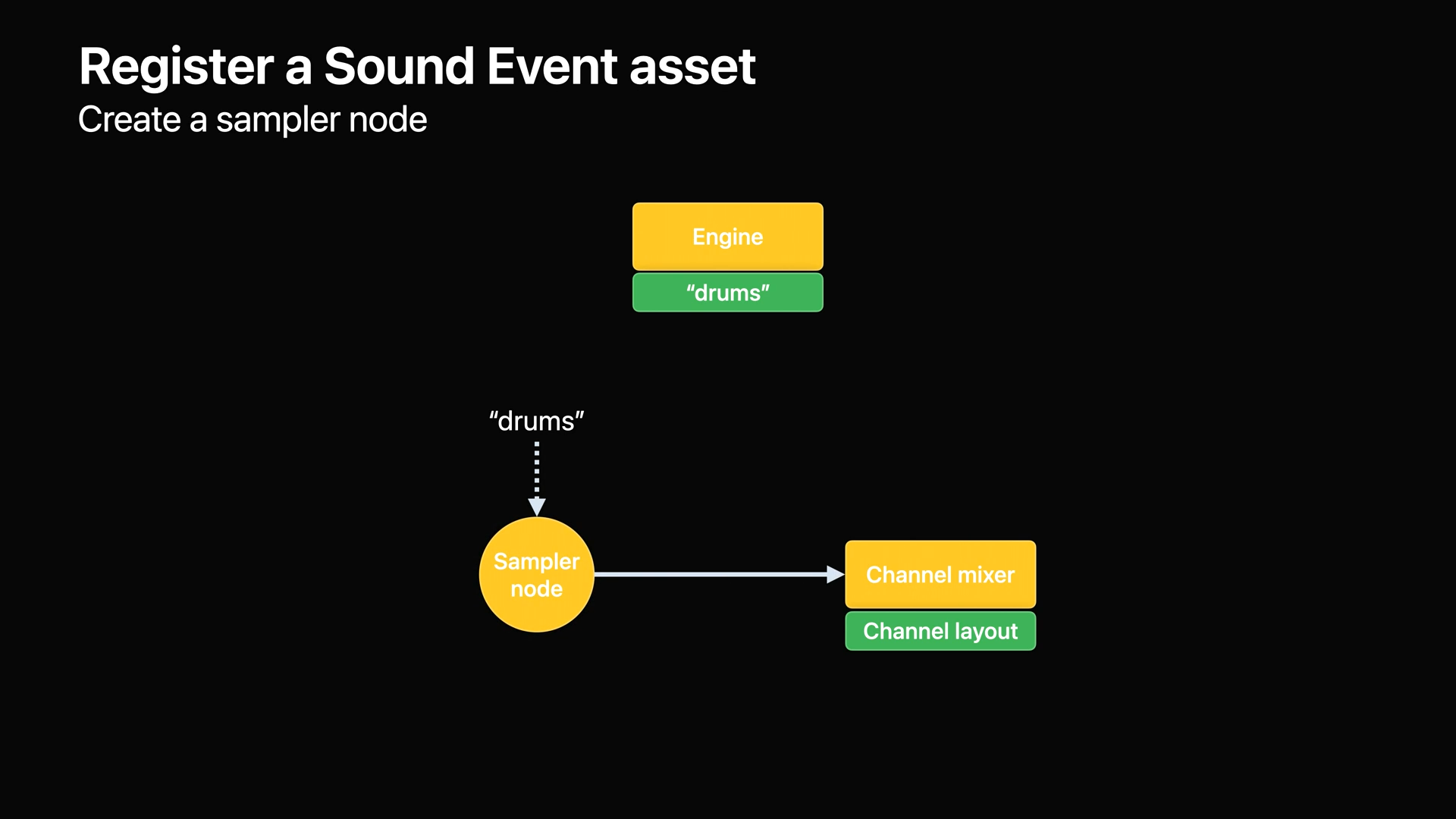
- 엔진에 사운드 리소스를 등록했으므로 사운드 이벤트를 구성합니다.
- 우선 채널 레이아웃에서 채널 믹서를 생성하고, 샘플러 노드를 생성합니다.
- 샘플러 노드는 등록된 사운드 리소스에 대한 이름을 가지며, 다운스트림 채널 믹서를 참조합니다.

- 다음으로 샘플러 노드가 올바르게 재생되도록 몇 가지 기본 속성을 설정합니다.
- 재생 모드는 샘플러가 오디오 파일을 반복할지 여부를 설정합니다.
- 보정 레벨은 믹스 내 샘플러의 음량을 설정합니다.
- 설정이 끝나면 샘플러 노드의 출력을 채널 믹서의 입력에 연결합니다.

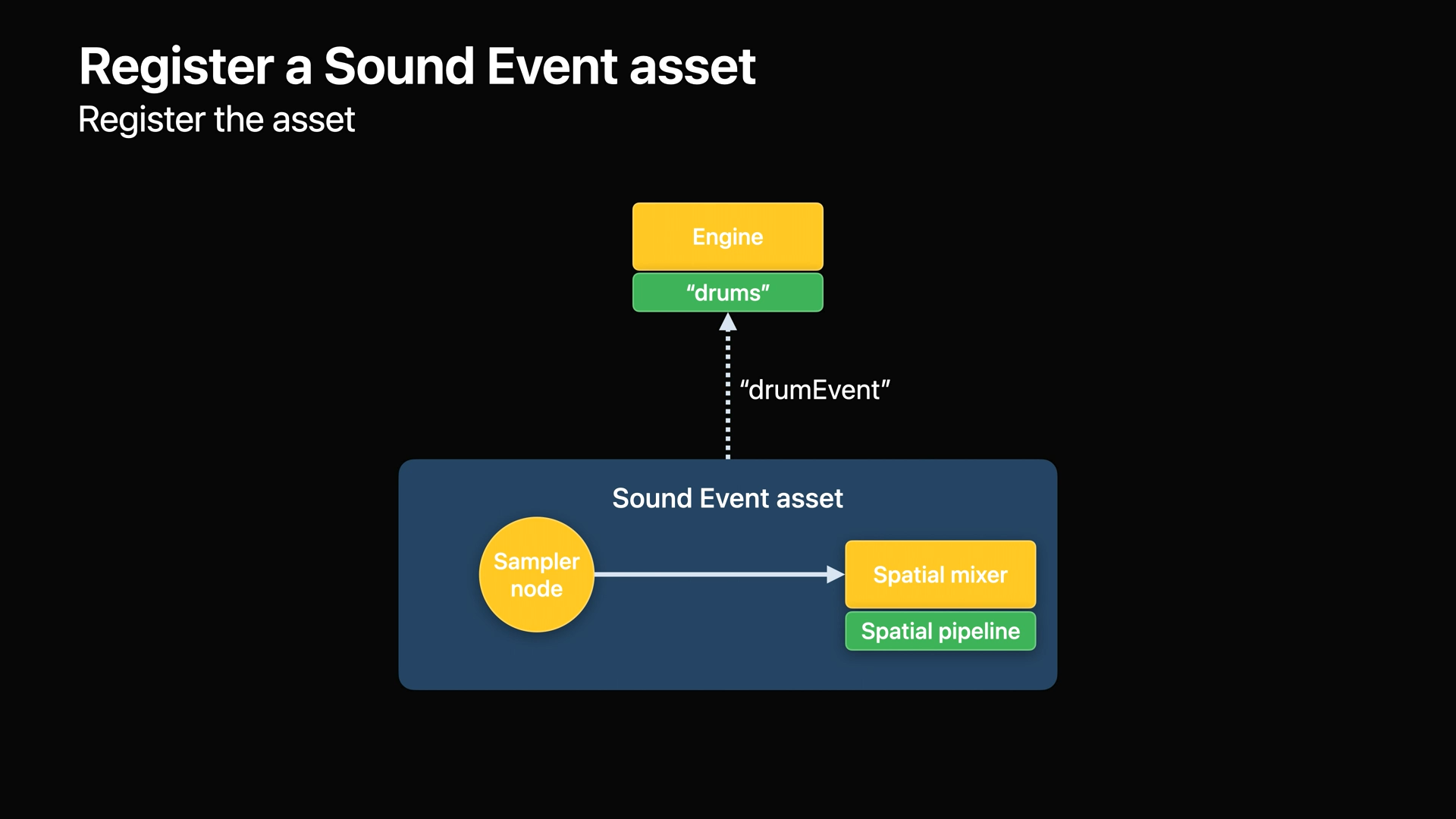
- 사운드 이벤트를 엔진에 나중에 참조하는 데 사용할 수 있는 "drumEvent"라는 이름으로 등록합니다.

- 위의 과정을 예제 코드로 보면 다음과 같습니다.
- 모노 ChannelLayoutTag에서 channelLayout을 생성합니다.
- 생성된 모노 channelLayout으로 채널 믹서를 초기화합니다.
- 샘플러 노드를 만들고 이전에 엔진에 등록한 모노 드럼 리소스를 참조하는 이름을 전달합니다.
- 샘플러 노드는 다운스트림 채널 믹서로 라우팅 됩니다.
- 재생 모드를 반복으로 설정하여 명시적으로 중지할 때까지 사운드가 계속 재생되도록 합니다.
- 일반적으로 편안하게 청취할 수 있는 설정인 CalibrationMode를 relativeSpl로, 레벨을 0 데시벨로 설정합니다.
- 마지막으로 soundEventAsset을 엔진에 등록하고 이름을 "drumEvent"로 전달하여 나중에 재생할 사운드 이벤트를 만들 때 참조할 수 있도록 합니다.
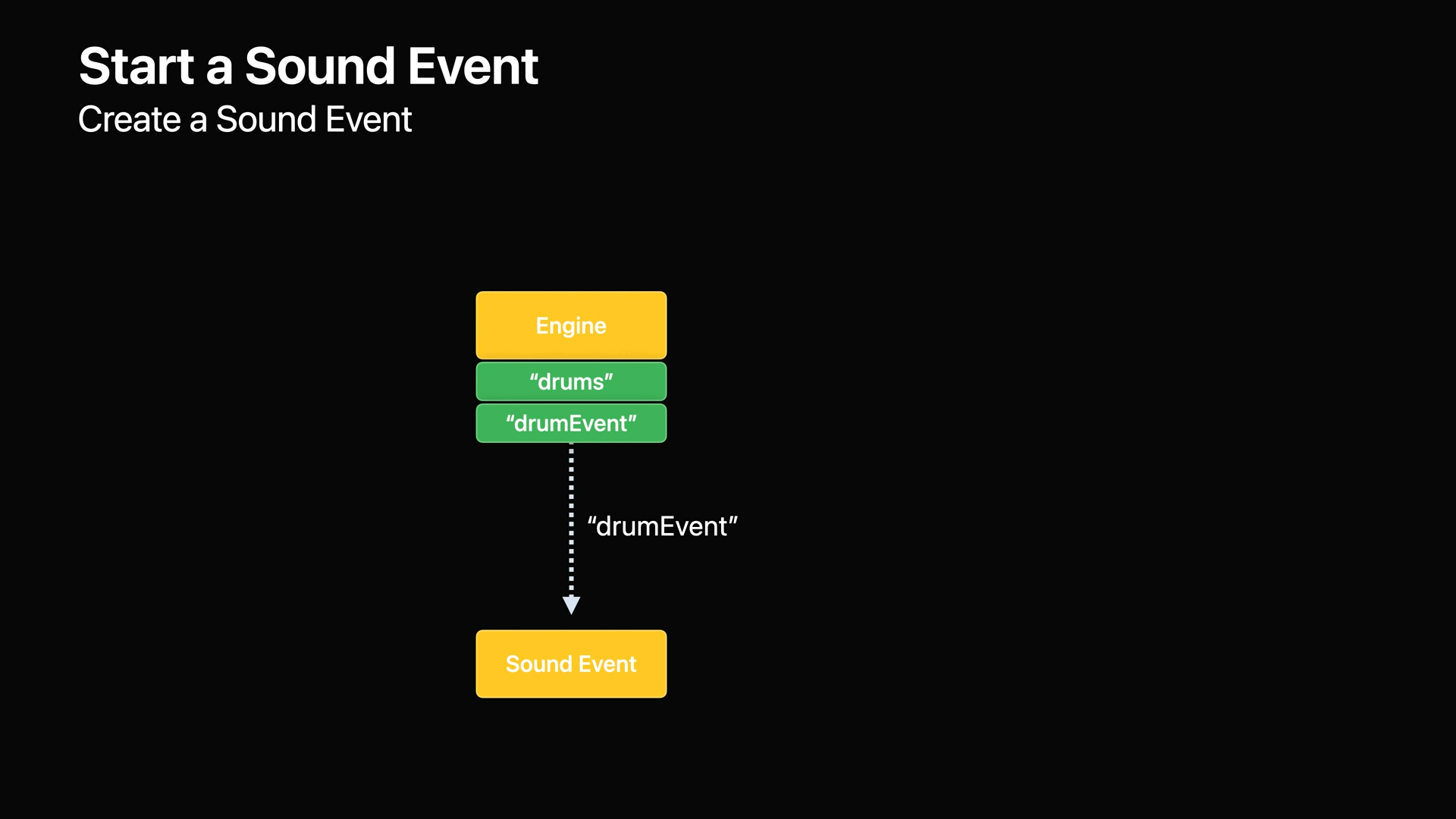
- 사운드 이벤트 에셋이 등록되면 인스턴스를 만들고 재생을 시작할 수 있습니다.
- 가장 먼저 할 일은 이름이 drumEvent인 등록된 사운드 이벤트 에셋에서 사운드 이벤트를 만드는 것입니다.
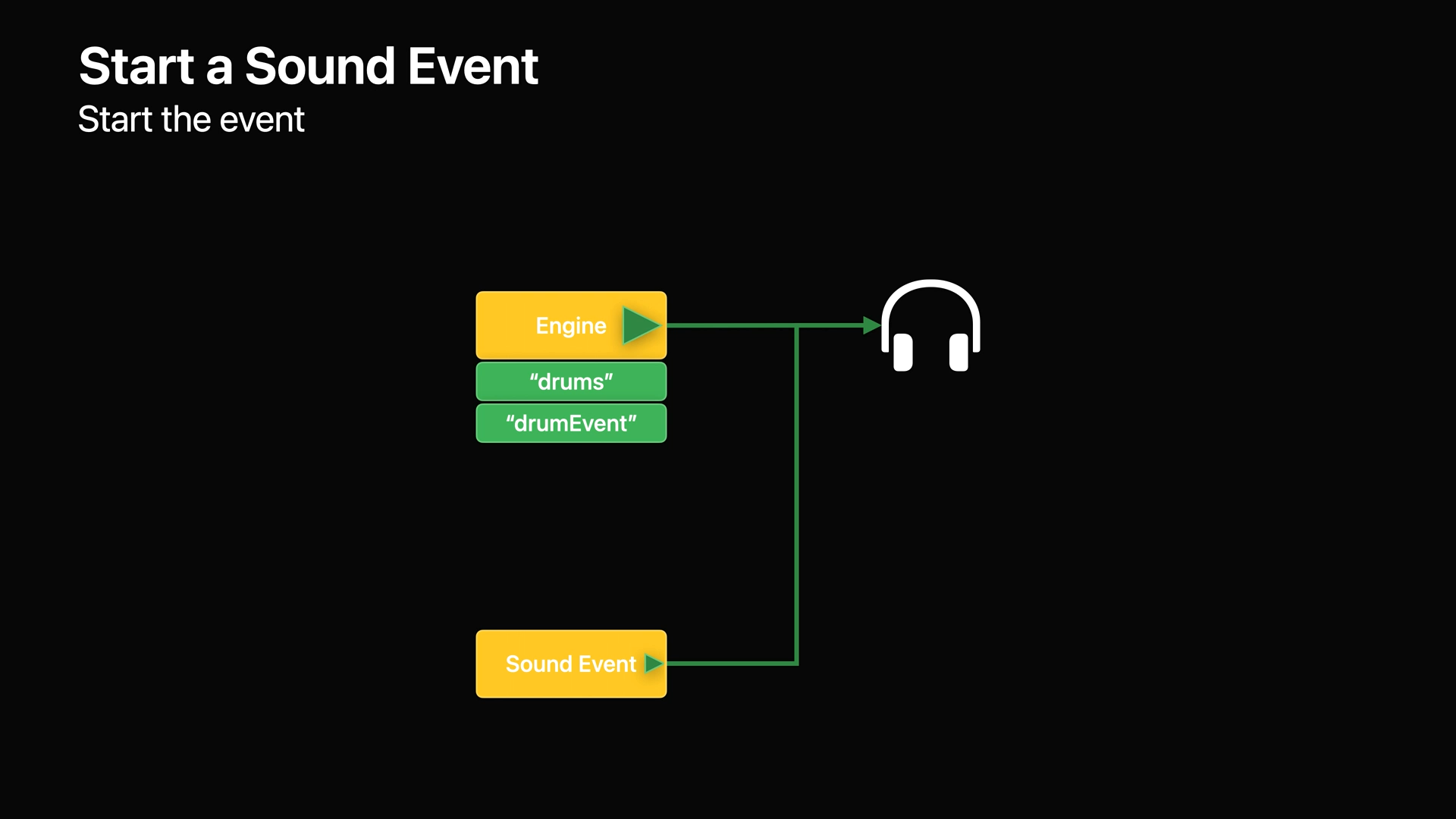
- 이제 사운드 이벤트가 있으므로 엔진을 시작하면 오디오 IO가 시작되어 출력 장치에서 오디오를 들을 수 있습니다.
- 마지막으로 사운드 이벤트를 시작하면 로드된 사운드 리소스가 샘플러를 통해 재생됩니다.
- 이 재생은 채널 믹서로 라우팅 되고 다시 현재 출력 형식으로 매핑되어 출력 장치에 재생됩니다.

- 이 과정을 예제 코드로 보면 등록된 사운드 리소스의 이름으로 SoundEvent를 생성하는 것을 볼 수 있습니다.
- 그다음 엔진과 사운드 이벤트를 순서대로 시작합니다.

- 사운드 이벤트 재생이 끝나면 엔진을 정리할 수 있습니다.
- 이를 위해서 먼저 사운드 이벤트를 중지합니다.

- 그럼 엔진을 정지하겠습니다. 이렇게 하면 오디오 IO가 중지되고 재생 중인 사운드 이벤트가 중지됩니다.

- 이름이 "drumEvent"인 사운드 이벤트 에셋의 등록을 해제합니다.
- 그다음 이름이 "drums"인 사운드 에셋의 등록을 해제합니다.
- 모든 리소스의 등록이 해제되면 마지막으로 엔진을 제거합니다.

- 이 과정을 코드로 보면 위와 같이 우선 stopAndInvalidate()를 호출하여 사운드 이벤트를 중지합니다.
- 그런 다음 오디오 IO를 중지하도록 engine의 stop()을 호출합니다.
- 다음으로 이름이 "drumEvent"인 사운드 이벤트 에셋의 등록을 해제하고 이름이 "drums"인 사운드 에셋의 등록 또한 해제합니다.

- 그다음은 PHASE에서 간단한 공간 오디오 경험을 구축하는 예입니다.
- 우선 사운드 이벤트 에셋을 엔진에 등록합니다.
- 이 예에서는 "drums" 사운드 이벤트가 등록된 엔진으로 시작합니다.
- 이제 기존의 간단한 채널 기반 재생에서 공간 오디오로 업그레이드하기 위해 공간 파이프라인을 구성합니다.
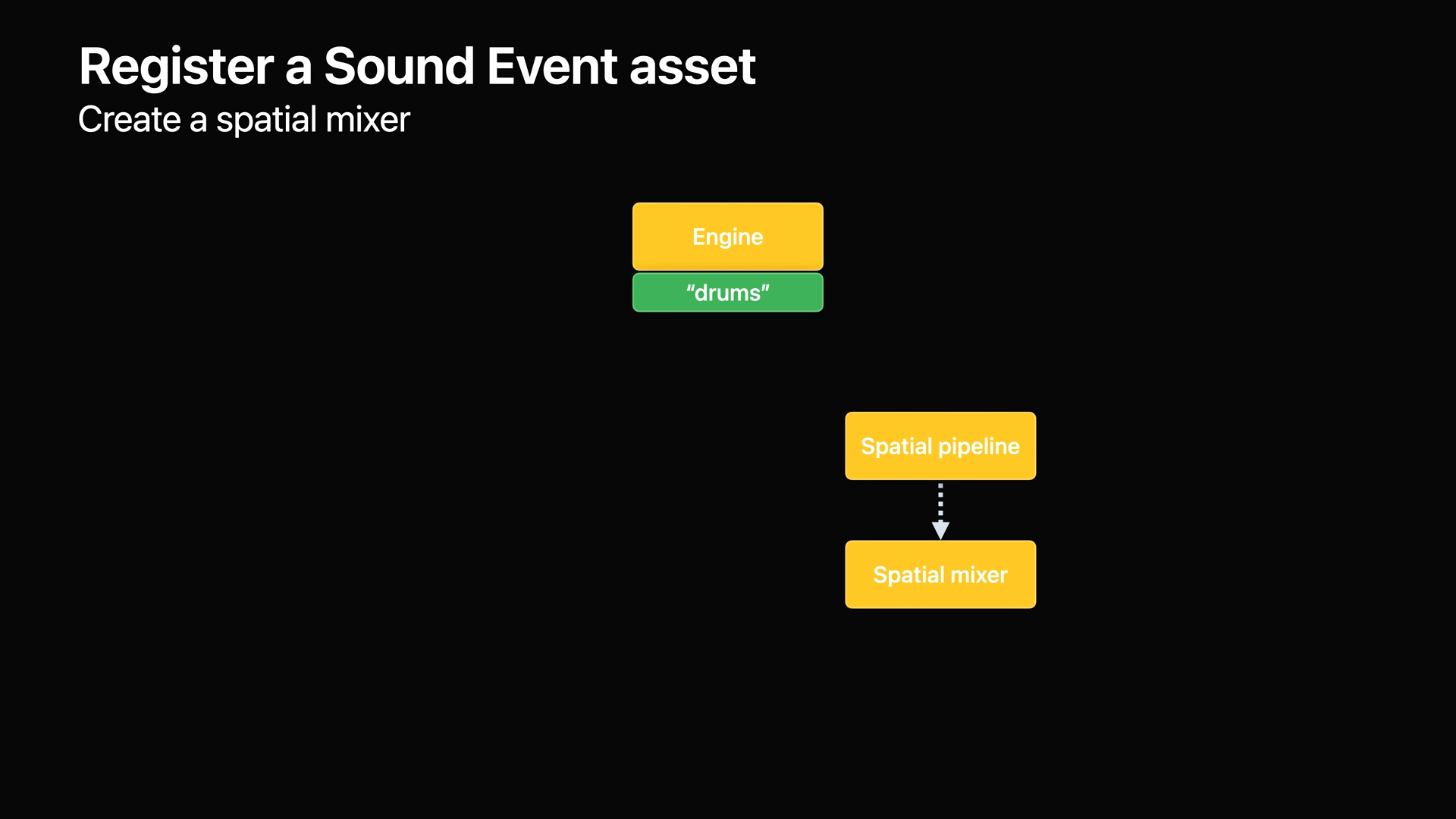
- 그다음 공간 파이프라인에서 공간 믹서를 생성합니다.

- 그다음 생성된 공간 믹서에서 몇 가지 기본 속성을 설정합니다.
- 이 예에서는 거리에 따른 레벨 감쇠를 제어하기 위해 거리 모델을 설정합니다.
- 방향성 모델도 설정하여 청취자와 사운드 소스의 각도를 기반으로 레벨 감쇠를 제어합니다.

- 그다음 샘플러 노드를 생성합니다.
- 샘플러 노드는 등록된 사운드 자산의 이름과 다운스트림 공간 믹서에 대한 참조를 사용합니다.
- 샘플러 노드 또한 몇 가지 기본 속성을 설정하겠습니다.
- 재생 모드 및 보정 수준, Cull Option을 설정합니다.
- Cull Option은 샘플러가 들리지 않을 때 PHASE가 무엇을 해야 하는지 알려줍니다.
- 설정이 완료되면 사운드 이벤트 자산을 엔진에 등록합니다.
- 이 예에서는 이전과 같이 "drumEvent"이름을 사용합니다.

- 이과정을 코드로 보면 우선 directPathTransmission 및 lateReverb를 옵션으로 하는 SpatialPipeline을 생성합니다.
- 그다음 lateReverb의 sendLevel을 설정하여 잔향 비율을 제어합니다.
- 후 잔향 시뮬레이션은 mediumRoom 설정을 선택합니다.
- 그런 다음 spatialPipeline을 사용하여 공간 믹서를 만들고 GeometricSpreadingDistanceModel을 공간 믹서에 할당합니다.
- 모델의 culDistance는 10미터로 설정하여 사운드 소스가 이 거리를 넘어서면 믹스에서 자동으로 컬링 하도록 합니다.
- 거리 감쇠 효과를 덜 강조하기 위해 rolloffFactor를 약간 조정합니다.

- 그다음 샘플러 노드를 만들어 이전에 만든 사운드 에셋을 나타내는 "drums" 이름을 전달합니다.
- 이 예에서는 playbackMode를 looping으로 설정하고, 보정 모드는 relativeSpl의 +12 데시벨로 설정하여 샘플러의 출력 레벨을 높입니다.
- 또한 culOption은 sleep으로 설정하였습니다.
- 마지막으로 soundEventAsset을 엔진에 등록하고 나중에 사운드 이벤트 생성을 시작할 때 참조할 수 있도록 이름 "drumEvent"를 전달합니다.

- 엔진에 사운드 이벤트 에셋을 등록하였으므로 시뮬레이션을 위한 장면을 만들어야 합니다.
- 이 예에서는 소스와 리스너 사이에 장애물을 배치하기 위해 먼저 리스너를 생성하고 Transform을 설정합니다.

- 씬 그래프 내에서 리스너를 활성화할 준비가 되면 엔진의 루트 개체나 그 자식 중 하나에 리스너를 연결합니다.

- 여기에서는 코드에서 리스너를 설정하기 위해 리스너를 생성합니다.
- 그런 다음 transfrom을 설정하며, 이 예에서는 리스너의 회전 없이 원점으로 설정합니다.
- 마지막으로 리스너를 엔진의 루트 개체에 연결합니다.

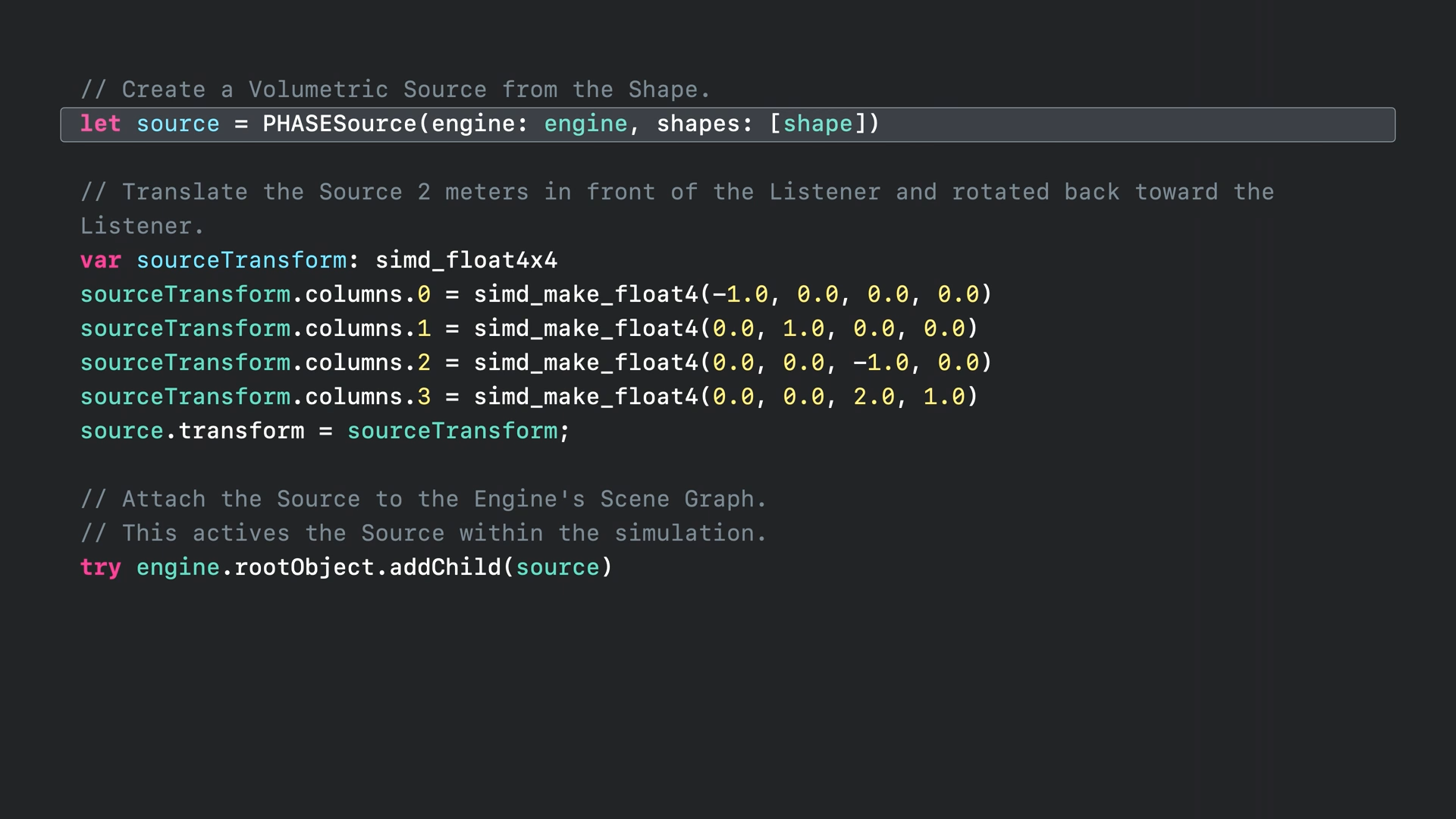
- 이제 체적 소스를 설정하기 위해 메쉬에서 모양을 만듭니다.
- 그런 다음 체적을 구성하기 위해 모양에서 소스를 만듭니다.

- 그다음 적절한 변환을 설정합니다.

- 장면 그래프 내에서 소스를 활성화할 준비가 되면 엔진의 루트 개체나 그 자식들 중 하나에 연결합니다.

- 이 예제에는 먼저 정 이십면체 메시를 만들고 대략 HomePod Mini 정도의 크기로 조정합니다.
- 그런 다음 메쉬에서 Shape를 만듭니다.
- 이 Sahpe는 동일한 메쉬를 공유하는 여러 인스턴스를 구성할 때 재사용할 수 있습니다.
- 다음으로 모양에서 체적 소스를 만듭니다.
- 이때 Shape를 입력으로 사용하지 않는 생성자를 사용하여 간단한 포인트 소스를 만들 수도 있습니다.
- 그런 다음 변환을 설정하여 소스를 청취자 앞에서 2미터 이동하고 청취자를 향해 다시 회전하여 서로 마주 보도록 하였습니다.
- 마지막으로 엔진의 루트 개체에 소스를 추가하였습니다.

- 이제 소리 방해물을 설정하기 위해 메쉬에서 모양을 만듭니다.
- 그다음 판지 재질을 만들어 모양에 할당합니다.
- 다음으로 모양에서 소리 방해물을 만들어 변환을 설정합니다.

- 장면 그래프가 준비가 되면 엔진의 루트 개체 또는 자식 중 하나에 연결합니다.

- 이 예제 코드에서는 먼저 boxMesh를 만들고 크기를 조정합니다.
- 그다음 메쉬에서 모양을 만들어 소리 방해물의 여러 인스턴스를 구성하는데 재사용할 수 있습니다.
- 다음으로 질감을 골판지로 설정하여 만듭니다.

- 그다음으로 모양에서 소리 방해물을 만듭니다.
- 그리고 변환을 설정하여 청자 앞에서 1미터 이동시키고 청자 쪽으로 다시 회전시켜 서로를 마주 보도록 합니다.
- 이렇게 하면 소스와 수신기 사이의 중간에 놓입니다.
- 마지막으로 엔진의 루트 개체에 연결합니다.

- 등록된 사운드 이벤트 에셋에서 사운드 이벤트를 만들고 장면 그래프의 소스 및 리스너와 연결합니다.
- 사운드 이벤트를 시작하면 소리 방해물 반대편에 있는 작은 소리 소스에서 재생되는 드럼 소리가 들립니다.
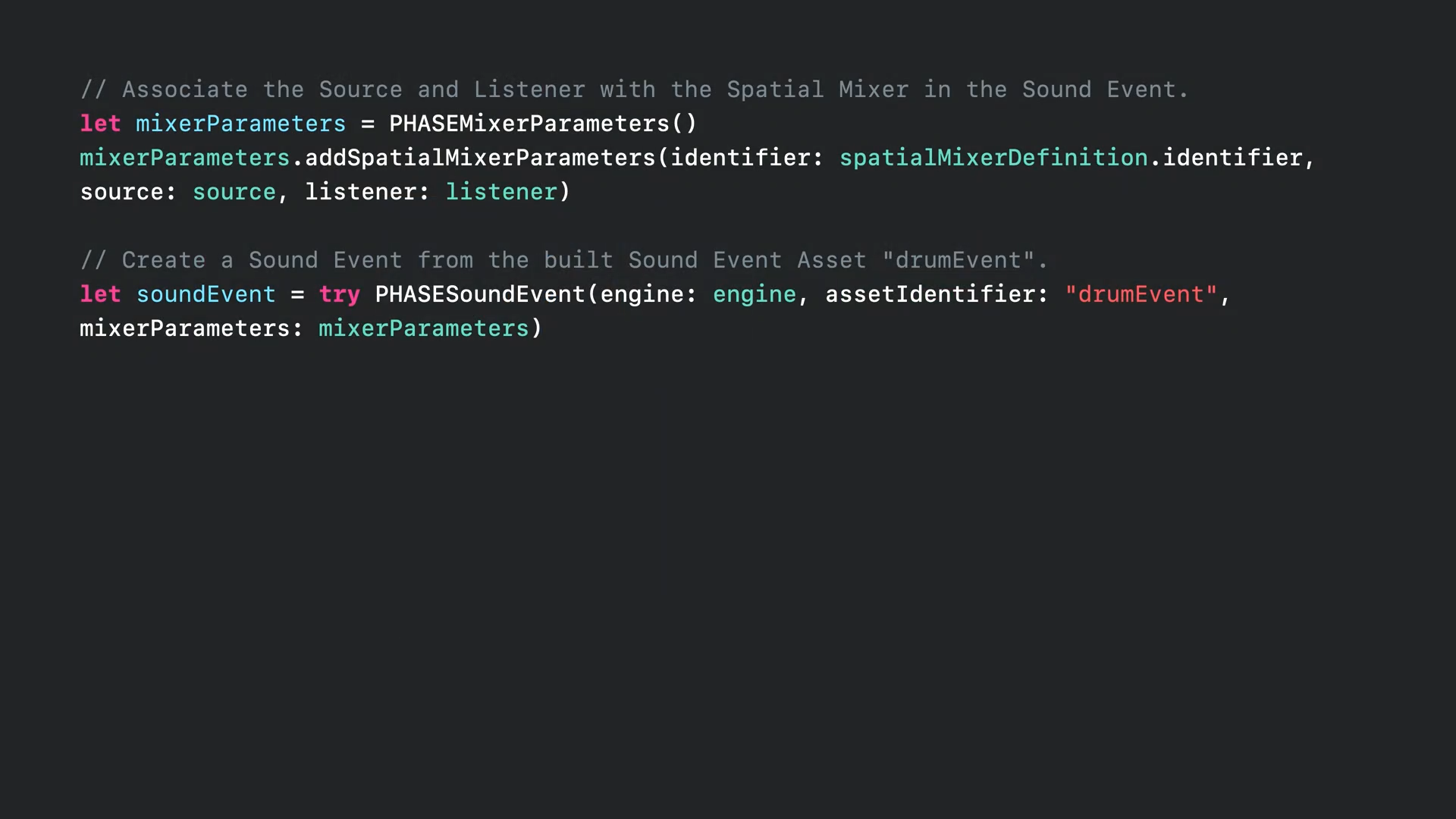
- 이 과정을 예제 코드로 보면 우선 소스와 리스너를 사운드 이벤트의 공간 믹서와 연결합니다.
- 그다음 "drumEvent"라는 등록된 soundEvent 에셋에서 soundEvent를 생성합니다.
- 나머지는 이전과 동일하게 엔진이 작동 중인지 확인한 다음 사운드 이벤트를 시작하면 됩니다.

- 복잡한 사운드 예제를 들기 위해 여기에서 우리는 다양한 유형의 표면을 가진 지형을 걷는 시끄러운 재킷을 입은 배우를 모델링할 것입니다.
- 이를 위해 먼저 삐걱거리는 나무의 발자국을 재생하는 샘플러 노드를 만듭니다.

- 코드로는 "footstep_wood_clip_1"이라는 이름의 등록된 사운드 에셋으로 샘플러 노드를 생성합니다.

- 이제 발자국 소리에 임의성을 추가하기 위해 약간 다른 발자국 소리를 재생하는 두 개의 하위 샘플러 노드가 있는 랜덤 노드를 만듭니다.

- 코드에서는 "footstep_wood_clip_1"와 "footstep_wood_clip_2"의 이름을 가진 두 개의 샘플러를 생성합니다.
- 그다음 랜덤 노드를 만들고 앞서 만든 샘플러를 자식으로 추가합니다.
- 가중치는 각 자식에 적용되며, 이 예에서는 첫 번째 노드가 두 번째 노드보다 두 배의 선택될 확률을 가집니다.
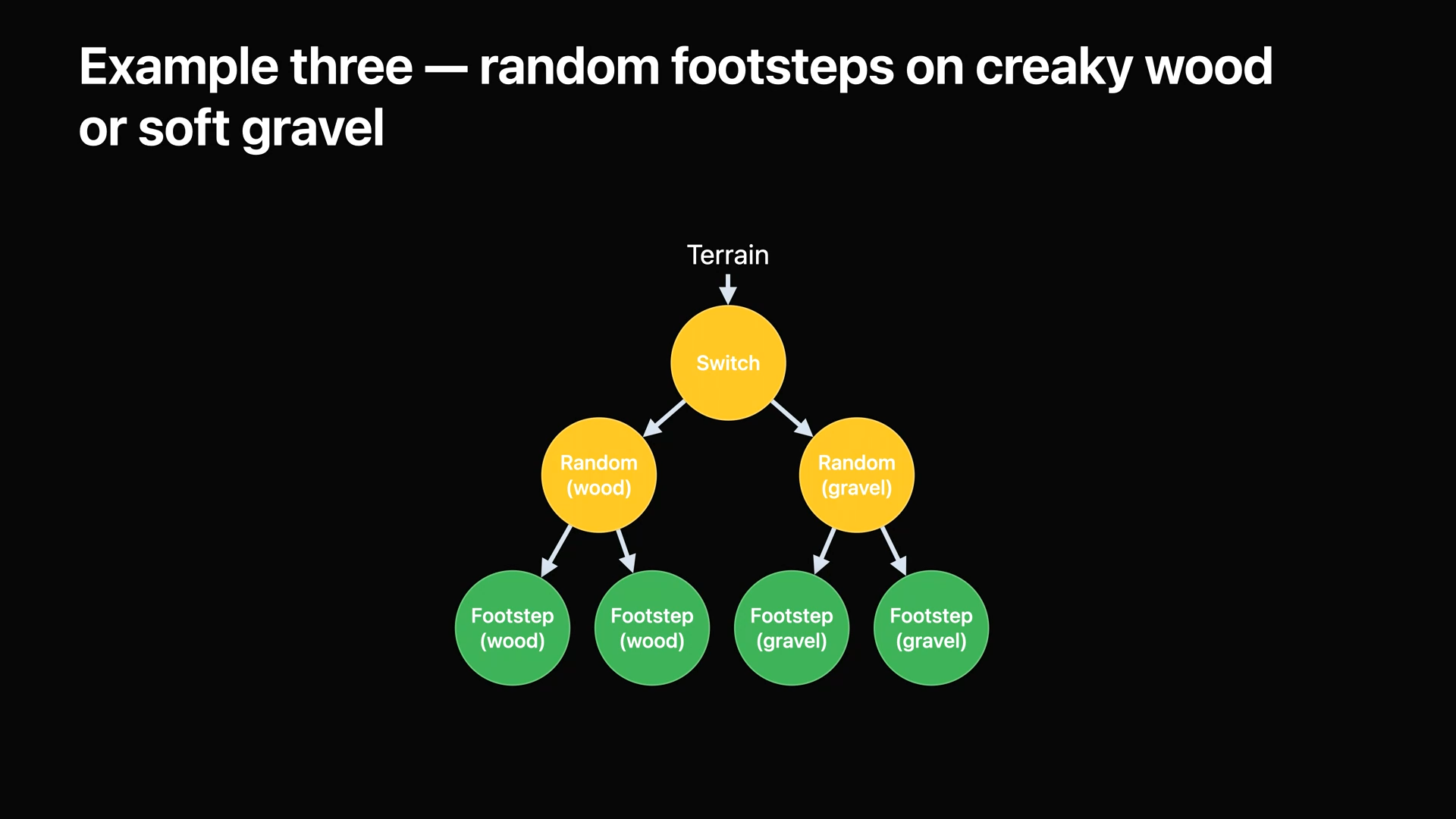
- 이제 지형 스위치를 추가합니다.
- 스위치 노드와 두 개의 랜덤 노드를 자식으로 생성하여 두 번째 임의의 노드에서는 자갈길의 발자국 소리를 재생합니다.
- 지형 매개변수를 사용하여 스위치 노드를 제어합니다.
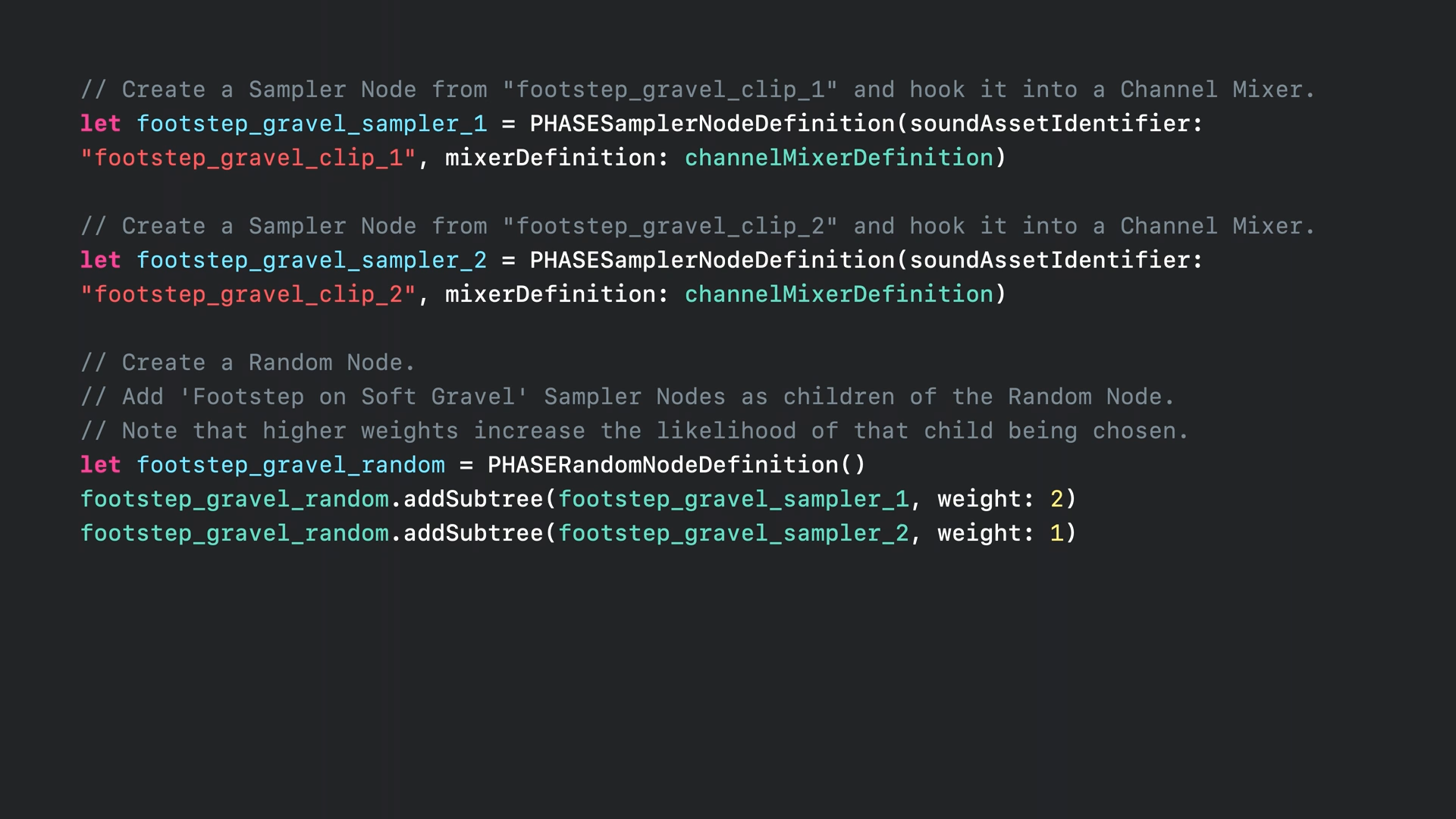
- 코드에서 앞에서 처럼 두 개의 샘플러 노드를 생성합니다.
- 그다음 랜덤 노드를 만들고 샘플러 노드를 자식으로 추가합니다.
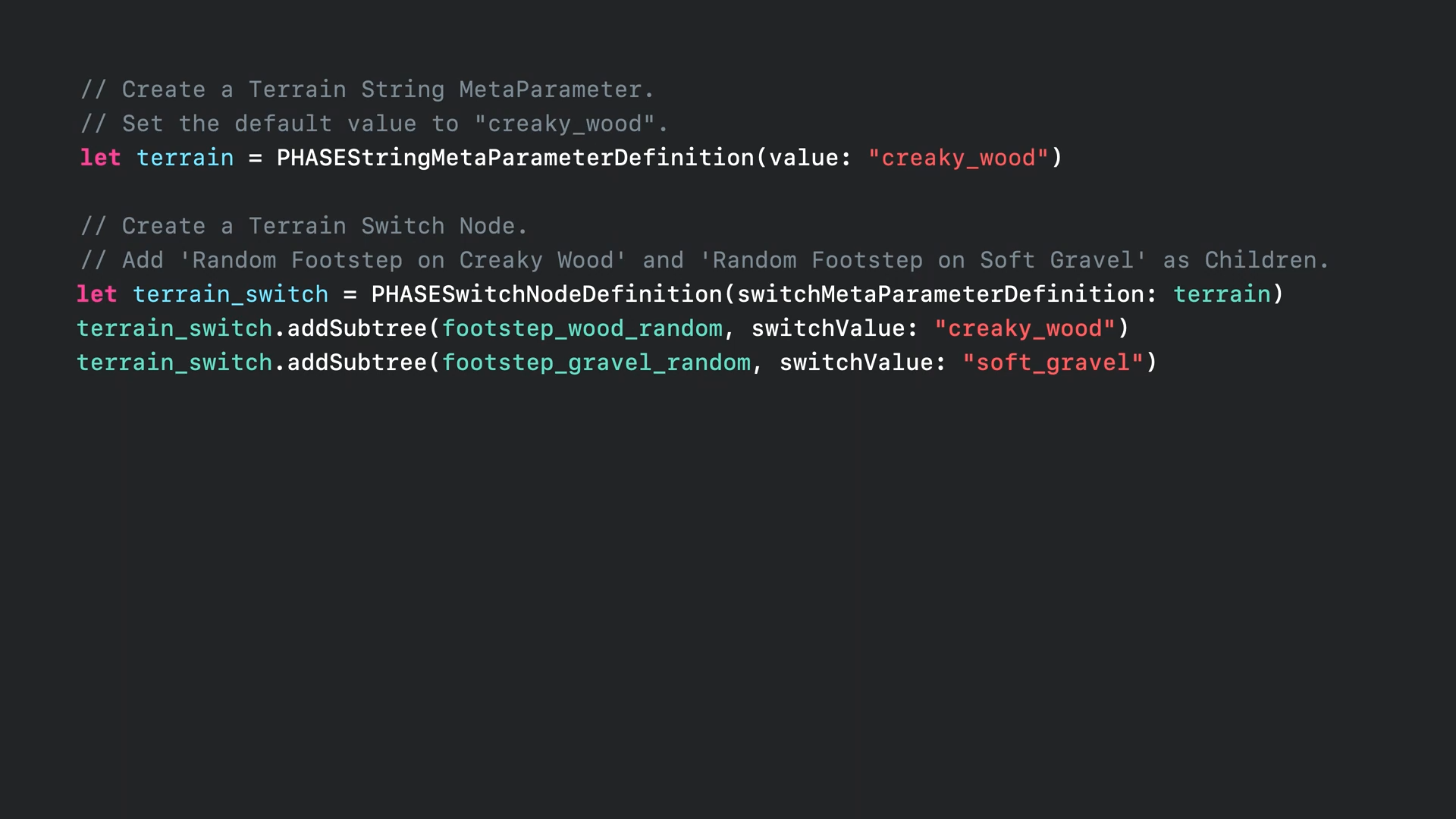
- 지형 매개변수를 생성하여 기본값으로 "creaky_wood"를 전달합니다.
- 그런 다음 스위치 노드를 생성하여 지형 매게 변수에 의해 제어되도록 합니다.
- 그다음 앞에서 생성했던 두 개의 랜덤 노드를 추가하면 지형에 따라 선택될 수 있게 할 수 있습니다.

- 그다음 물 튀기는 소리를 위한 노드를 추가합니다.
- 그다음 블렌드 노드를 생성하여 지형 소리와 물 튀기는 소리를 섞습니다.
- 마른 발자국 소리와 물이 튀는 소리 사이의 혼합은 얼마나 젖었는지를 뜻하는 매개변수에 의해 결정됩니다.

- 예제 코드에서 두 개의 샘플러 노드를 생성하여 첫 번째는 "splash_clip_1", 두 번째는 "splash_clip_2"으로 생성합니다.
- 생성한 노드들은 랜덤 노드의 자식으로 추가합니다.

- 그다음으로 젖은 정도를 나타내는 매개변수를 범위는 0 ~ 1이고 기본값은 0.5로 생성합니다.
- wetness 매개변수로 제어되는 혼합 노드를 만들고 이를 통해 젖은 지형을 시뮬레이션할 수 있습니다.
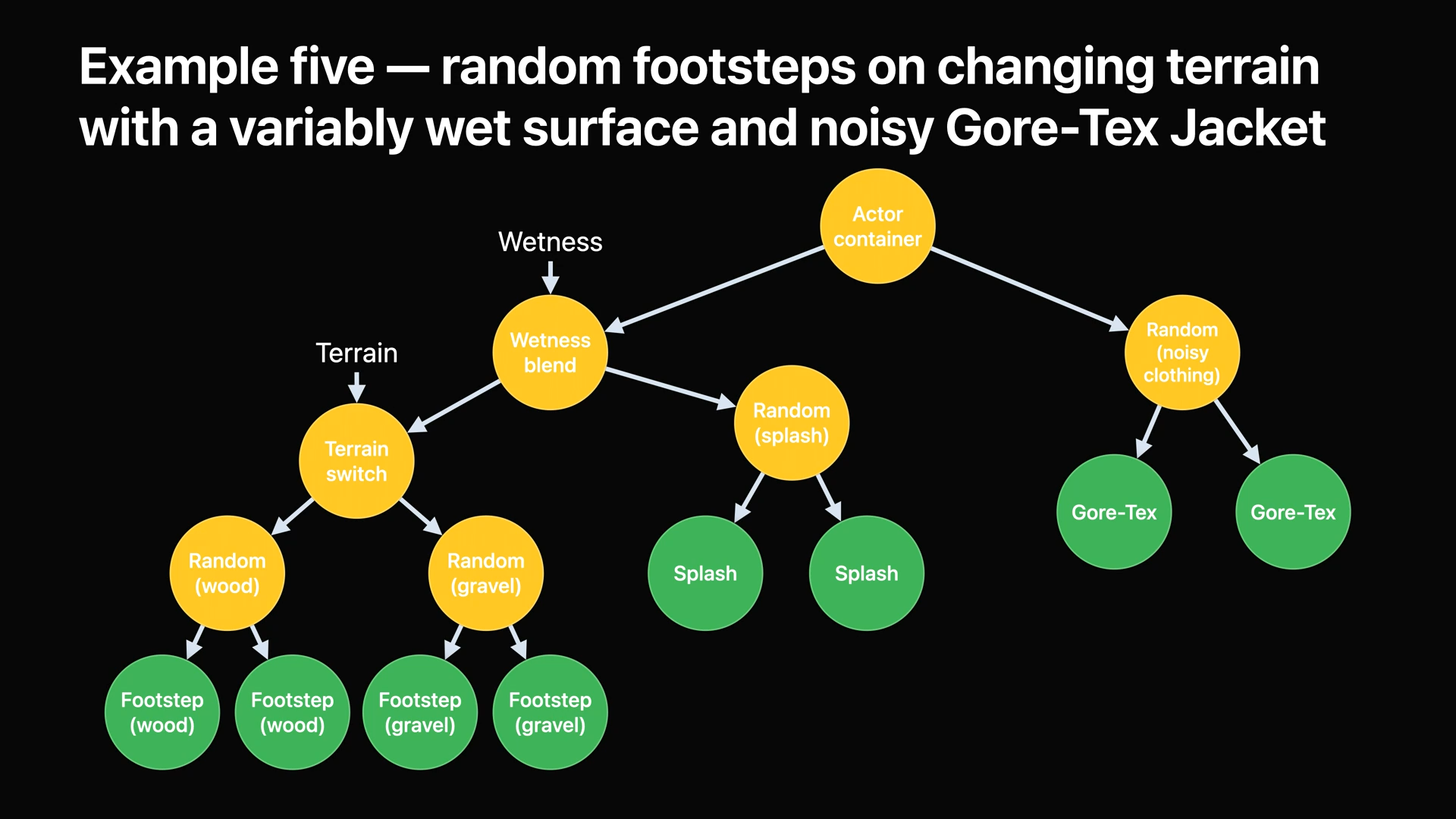
- 마지막으로 시끄러운 옷 소리를 재생하는 노드를 만들어 컨테이너 노드에 연결합니다.

- 예제 코드에서는 지금까지처럼 마찬가지로 두 개의 샘플러 노드를 생성합니다.
- 각각 "gortex_clip_1", "gortex_clip_2" 이름의 사운드 자산을 적용하고 랜덤 노드를 생성하여 추가합니다.

- 마지막으로 actor_container 노드를 생성하여 이전에 만든 wetness_blend, noise_clothing_random 두 개의 노드를 추가하면 됩니다.
'WWDC > WWDC 2021' 카테고리의 다른 글
| WWDC 2021 - Elevate your DocC documentation in Xcode (0) | 2021.10.27 |
|---|---|
| WWDC 2021 - Discover concurrency in SwiftUI (0) | 2021.10.19 |
| WWDC 2021 - Discover account-driven User Enrollment (0) | 2021.10.13 |
| WWDC 2021 - Discover Metal debugging, profiling, and asset creation tools (0) | 2021.10.07 |
| WWDC 2021 - Diagnose Power and Performance regressions in your app (0) | 2021.09.28 |
'WWDC/WWDC 2021' Related Articles
more




Comments